Special thanks to Haven for guidance on my video generation journey!
 Haven Feng
Haven Feng
Also shoutout to Jameson for being a comrade on this quest!
 Jameson Crate
Jameson Crate
Two months ago, I was a clueless undergrad diving into autoregressive video generation. Every paper I read claimed to be SOTA, but I couldn’t answer basic questions: Are these methods actually the same thing? Which is better in certain situations and why?
This post organizes my aha moments. It guides you through the space as if you’re discovering it for the first time, giving motivation for the why and how things relate to each other.
I first cover key papers and discoveries in image generation, then present a unified view of the autoregressive video generation landscape. Hopefully I can give a bird’s-eye view of the video generation space so it is easier for other beginners to get into it!
The Landscape of Image Generation#
Before diving into video generation, we need to understand how image diffusion models work. If you’re already familiar with DDPM and DDIM, skip to video generation.
DDPM#
TL;DR: DDPM learns to reverse a noising process. The clever part: maximizing ELBO (minimizing KL divergences at each noise level) reduces to simple L2 loss on noise prediction. This makes diffusion models practical to train.
Denoising Diffusion Probabilistic Models (DDPM) introduced a principled framework for generating images by learning to reverse a gradual noising process. The key insight: if we can learn to denoise images at every noise level, we can start from pure noise and iteratively denoise to generate novel images.
DDIM#
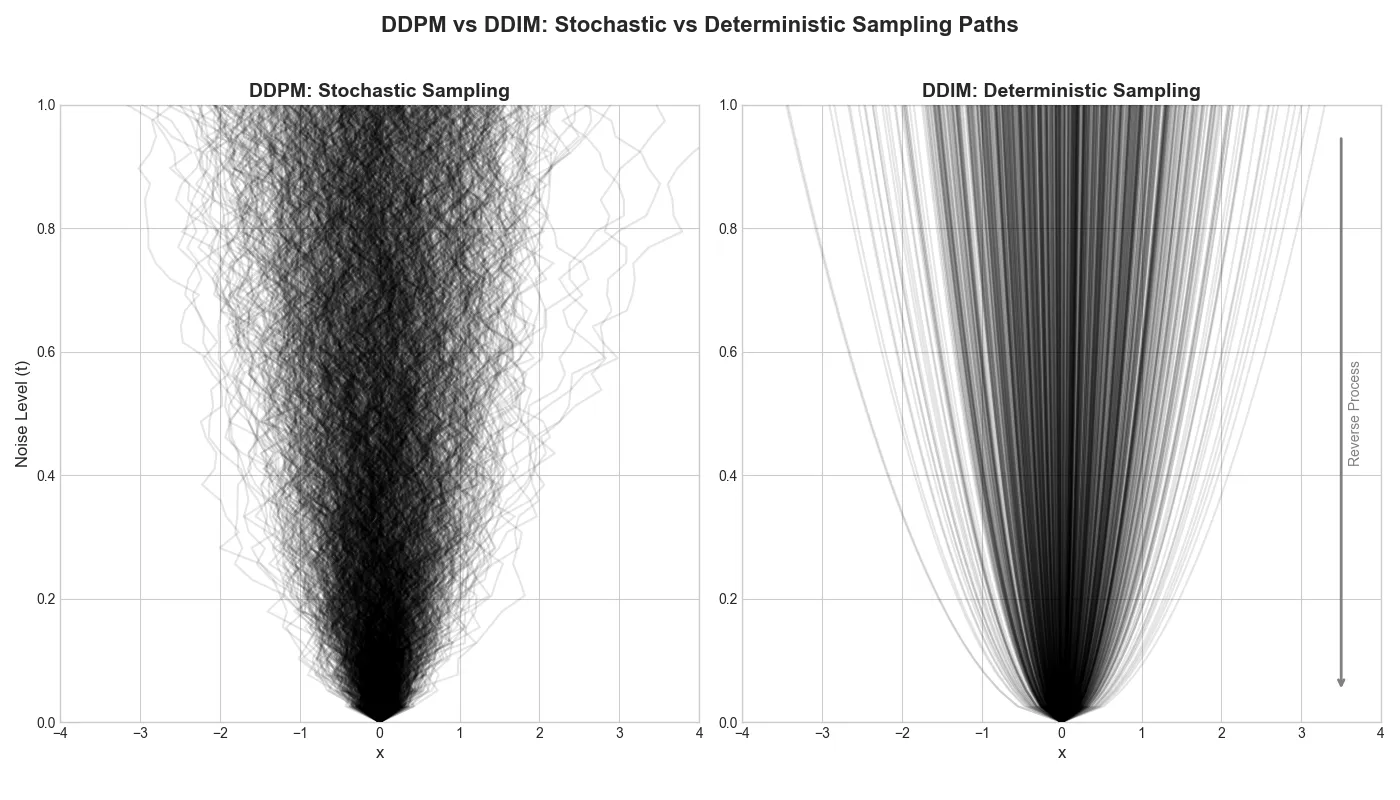
TL;DR: DDIM’s breakthrough: diffusion can be modeled as an ODE, not an SDE. Same training as DDPM, but 10-50x faster sampling by removing stochasticity. This deterministic view is the foundation for modern samplers.
Denoising Diffusion Implicit Models (DDIM) made a crucial discovery: DDPM’s reverse process doesn’t need to be stochastic. By reparameterizing the reverse process, we can prove deterministic sampling creates the same marginal distributions (images over noise levels) as DDPM.
▶ The Key Innovation: Controlling Stochasticity
DDPM’s reverse process (backward step) is:
$$ q(x_{t-1} \mid x_t, x_0) = \mathcal{N}(x_{t-1}; \tilde{\mu}_t(x_t, x_0), \tilde{\beta}_t I) $$where the mean is deterministic but there’s always stochastic noise \(\tilde{\beta}_t\).
DDIM generalizes this by introducing a parameter \(\sigma_t\) that controls how much stochasticity to add:
$$ q_\sigma(x_{t-1} \mid x_t, x_0) = \mathcal{N}(x_{t-1}; \mu_\sigma(x_t, x_0), \sigma_t^2 I) $$where the mean is:

The magic: the marginal distributions \(q_\sigma(x_t)\) are identical for any choice of \(\sigma_t\), as long as \(\sigma_t^2 \leq 1 - \bar{\alpha}_{t-1}\).
▶ From Stochastic to Deterministic
The critical insight: we can set \(\sigma_t = 0\) to get a deterministic reverse process:

This is an ODE (ordinary differential equation) instead of an SDE (stochastic differential equation)! Given the same starting noise \(x_T\), we always get the same output \(x_0\).
Special cases:
- \(\sigma_t = \sqrt{\tilde{\beta}_t}\): Recovers DDPM (fully stochastic)
- \(\sigma_t = 0\): Pure deterministic sampling (DDIM)
- \(0 < \sigma_t < \sqrt{\tilde{\beta}_t}\): Interpolates between the two
Key takeaway: DDIM showed that diffusion models are solving an ODE, not fundamentally requiring stochasticity. This deterministic view is conceptually cleaner and practically faster, making it the foundation for modern diffusion samplers.
▶ The Natural Euler perspective
Speaking of conceptually cleaner, we can massively simplify our training by getting rid of the alphas and betas. Any linear transformation of the noise schedule is equivalent, so we can use the linear schedule (using t and 1-t) and retroactively (like our DDPM DDIM stochasticity) decide what noise schedule we want to use at inference time.
Straighter lines = lower integration errors when we sample our ODE = less steps needed for the same quality = faster inference time with less compute
The rectified flow blogs and sander.ai blog go into great detail and have fantastic explanations for this so I will link them here. Please check them out.

One tip for visualizing the schedules is that the blue line (standard deviation of the noise factor) is the trajectory your samples along a conditional vector field (if your target distribution is just a single point). The rectified flow in this case gives you the straight line for this case (rightmost graph). The green line \(\sqrt{\text{Var}(x_t)}\) gives you the trajectory samples will follow if your source and target distributions are both unit gaussians. The cosine schedule gives the straightest lines in this case.
Determining the schedule that yields the straightest path is not trivial for arbitrary distributions, and hence the need for hyperparameter search to yield the straightest green lines from your target distribution to your noise distribution. Your target distribution most likely doesn’t have the symmetries of a gaussian distribution, so the optimal noise schedule still will most likely not get you exactly straight lines.
Score matching#
Under construction. https://arxiv.org/abs/2011.13456 continuous view of diffusion
The unified framework of image generation (EDM paper)#
under construction.
Fun connections#
- diffusion is spectral autoregression
- Distillation converges faster than training from scratch even for the same architecture because the variance of the distillation loss is significantly reduced
From Images to Videos: The Bridge#
Now that we understand how image diffusion works (minimizing KL divergences via L2 loss), let’s see how these same principles extend to video generation. The key question: when generating videos frame-by-frame, how should we condition on past frames? Should they be clean, noisy, or generated?
This leads us to different training methods (BiD, TF, DF, SF) paired with different losses (L2, GAN, DMD). At first glance, they seem very different. But here’s the surprising insight: they’re all optimizing the same thing—just weighted differently.
A Unified Perspective of Video Generation Methods#
In the diffusion world, it turns out over and over again that there are many different seeming methods that all turn out to be equivalent with some small difference in the details.
One example is that different parametrizations of diffusion models (\(x_0\) prediction, e predictions, v prediction), flow matching, and score matching are equivalent. Using each of these objectives turns out to just emphasize different noise levels over others (see my explanation above for details). So from now on when we say predict \(x_0\) (or any of the other objectives) and compute the loss, know that you can just swap in a different parametrization and you would end up with the same thing up to some changes in which noise levels our loss emphasizes.
Another example is that different noise schedules (as long as they are an affine transformation of one another) are equivalent. You can train your model using the rectified flow schedule (the t and (1-t) one) and later use a different schedule to sample no problem. So you might as well just train using the simple noise schedule and then search for the best schedule after training to minimize ODE solver errors. The rectified Diffusion blog has a great explanation for this.
Yet another example is the equivalence between DDPM and DDIM (stochastic sampling vs deterministic sampling) explained above
So when confronted with different video generation training methods: Teacher Forcing with L2 loss (TF+L2), Diffusion Forcing with L2 loss (DF+L2), Self Forcing with DMD loss (SF+DMD), Self Forcing with GAN loss (SF+GAN), Bidirectional training with L2 loss (BiD+L2), Approximated CausVid (DF+DMD) …
it is natural to wonder: are they equivalent somehow?
The answer is yes… (almost)
They are almost all optimizing a combination of KL divergences across noise levels:
The Unified Framework: Method + Loss → KL Divergence#
Legend:
- 🔵 Forward KL \(\mathrm{KL}(p_{data} \parallel p_{model})\): Mode-covering, trains on ground truth data
- 🔴 Reverse KL \(\mathrm{KL}(p_{model} \parallel p_{data})\): Mode-seeking, trains on generated data
- 🟣 JSD: \(\mathrm{JSD}(p_{data} \parallel p_{\text{model}}) \): Symmetric mix of the two
| Type | Training Method | Loss | What It Optimizes | Papers |
|---|---|---|---|---|
| 🔵 | DF | L2 | \(E_{forward} \big[ \mathrm{KL}(p_{data} \parallel p_{\text{model}}) \big]\) | Diffusion Forcing |
| 🔴 | SF | DMD | \(E_{backward} \big[ \mathrm{KL}(p_{model} \parallel p_{\text{data}}) \big]\) | Self Forcing, Causvid (not approximated) |
| 🟣 | SF | GAN | \(E_{noise} \big[ \mathrm{JSD}(p_{data} \parallel p_{\text{model}}) \big]\) | Self Forcing |
| 🔵 | TF | L2 | \(E_{forward} \big[ \mathrm{KL}(p_{data} \parallel p_{\text{model}}) \big]\) | Taming Teacher Forcing |
| 🔵 | BiD | L2 | \(E_{forward} \big[ \mathrm{KL}(p_{data} \parallel p_{\text{model}}) \big]\) | WAN 2, Veo3 |
| 🟡 | DF | DMD | \(E_{forward}\left[ \int pushforward(x) \log\left(\frac{p_{\mathrm{model}}(F(x,t),t)}{p_{\mathrm{data}}(F(x,t),t)}\right) dx \right]\) | Causvid (approximated) |
| ❓ | SF | SiD | ? | Self Forcing |
Training Methods:
- DF (Diffusion Forcing): Train on ground truth frames with independent noise per frame
- SF (Self Forcing): Train on model-generated frames (self-rollout)
- TF (Teacher Forcing): Train on ground truth frames, sequentially denoise last frame only
- BiD (Bidirectional): Train all frames synchronously at same noise level
Note: 🟡 means hybrid that doesn’t fit the forward/reverse KL framework cleanly.
Key Patterns to Notice:
- All L2 methods (DF, TF, BiD) → 🔵 Forward KL (train on ground truth)
- SF + DMD → 🔴 Reverse KL (train on generated data)
- SF + GAN → 🟣 JSD (measuring divergence of data and model vs a mix of the two)
- Training method = what data you train on, Loss = what objective you optimize
▶ What is \(E_{forward} \) and \(E_{backward} \) ?
\(E_{forward}\) is the expectation over the forward process. This forward process is just how noisy latents are generated. So the forward process in DF would be adding an independent random noise level to every ground truth frame. In SF the forward process is adding an independent random noise level to every generated frame. In TF the forward process is choosing a random frame, making all frames after fully noised, and making the chosen frame some random amount of noise.
The definition of the forward process is inspired from the DF paper:
In fact, all I did was translate the concept from the DF paper to the other methods.
\(E_{backward}\) is the expectation over the backward process. This backward process is when the model partially denoises frames. The model starts with noisy latents and generates samples by denoising them to various noise levels (or completely to clean frames).
Both are ways to generate noisy latents, they just differ in whether it’s from the model distribution or data distribution
The loss landscape would change depending on what the exact divergences are being optimized but the optimal distributions created by the model is identical across methods.
The loss landscape often matter a lot however, as things such as limited model capacity, compute, data, early stopping, and often lead to suboptimal models in practice.
Before diving into the proofs, let’s build intuition for what each training method and loss function actually does. Understanding these building blocks will make the unified framework clear.
What are the training methods for video generators today (BiD, TF, DF, and SF)?#
TL;DR: The training method determines how you condition on past frames:
- BiD: Denoise all frames simultaneously (like image diffusion, but for videos)
- TF: Use clean ground truth context, denoise one future frame
- DF: Use noisy ground truth context (noise = continuous mask)
- SF: Use self-generated frames to eliminate exposure bias

▶ What is TF (Teacher Forcing)
Autoregressive video generation (AR video gen) addresses attempts to solve all of the above problems while still having high quality and fast generation of videos.
The first AR video gen method we may think of could be inspired by the LLM field. In the LLM field, the transformer decoder architecture with a causal mask has been used to predict the next language token given the previous language token. If we steal this idea we can come up with the following: predict the next image frame given the previous video frames.
If we implement this idea, we would give our models some context frames from our video dataset and then present it with a frame with gaussian noise and ask it to predict the denoised version.
But as we learned from diffusion and variational autoencoders, asking the model to predict the clean image given noise in one step leads to blurry images. So we can use the idea of decreasing noise levels from image generation to add some amount of noise to the last frame and predict the clean frame.

This is called teacher forcing. The definition of teacher forcing is predicting a continuation of the sequence given ground truth (teacher) frames as conditioning. This is exactly how LLM pretraining is done.
The astute reader may notice the training with teacher forcing for video has trouble in parallelization compared to language modeling. Teacher forcing in language with transformers can just have an upper triangular binary causal mask to train O(N) examples at the same time. (e.g. “The cat in the hat” snippet with one forward pass would predict The -> cat, The cat -> in, The cat in -> the, The cat in the -> hat)
But for video generation we denoise with different levels of noise. So our context will be full of partially noised video frames if we tried to parallelize our training naively.
This can be overcome with a special attention mask where we have the ground truth frames first, then concatenate frames with varying amount of noise after and having a special teacher forcing attention mask:

The goal here is to let every noise frame look at all previous clean frames only and not look at previous noisy frames.
With this attention fix we are able to train our teacher forcing video generation model by combining ideas from both LLMs and image diffusion.
But we have two problems:
- Our attention mask seems more complicated than it needs to be (our attention mask is roughly 4 times bigger than a simple causal mask)
- As we roll out our video using this model, we find that the quality of frames gets bad very quickly the longer we generate for
The reason for the second point is exposure bias:
Exposure bias#
Exposure bias is when a model is trained on ground-truth data, but at inference time it must rely on its own predictions as input. This is a problem because errors can accumulate over time and the past frames we condition on look nothing like any video the model was trained on so the model is out of distribution.
This is also true for language models, but the space of language is much more compressed than images, and so just brute force training on massive data seems to have brought almost all language context into distribution. To see exposure bias yourself try out [youaretheassistantnow.com] to see how fast you can break the language model with out of distribution context. The website swaps the role of the User and Assistant, so acting very different than a “helpful assistant” to the models queries reveals how exposure bias can break autoregressive generation by taking the context out of training distribution.
▶ What is DF (Diffusion Forcing)
A way we could kill two birds with one stone is to allow different noise levels in our history.
First, our attention mask can be the simple binary causal attention mask from language modeling or no mask at all. This is because our context can consist of frames at independent random noise levels, so we no longer have to hide the noisy past frames we want to train in parallel from each other. Noise serves as a continuous mask with no noise being no mask and pure noise being a complete mask.

Second, our model trains on random levels of noise injected into our history, which we can set at test time to have a bit of noise (maybe add a bit of noise to each frame the model generates before feeding it back to the model). This brings the distributions of the history when using self generated frames vs ground truth frames closer (helping exposure bias).

This means we can inject a little bit of noise to our past frames when generating videos to help keep our self generated video (self rollout) in distribution.
As a bonus we unlock different denoising strategies at inference time, which reveal that teacher forcing and bidirectional video generation is actually a subset of diffusion forcing.
Teacher forcing = setting all context frames to no noise and sequentially denoising the last frame Bidirectional video generation = setting all frames to full noise and then denoising all frames in lockstep.
We also unlock a strategy to tradeoff denoising timesteps and latency: We can have a monotonically decreasing noise level. Lets say we do a context length of 5 frames and have noise levels of [0, 0.25, 0.5, 0.75, 1]. We can do an inference step and then slide our window forward by 1 frame. This allows us to produce 1 frame per function evaluation.
The larger the context length we go from 0 noise to 1 noise level ([0, 0.5, 1] vs [0, 0.2, 0.4, 0.6, 0.8, 1]), the more frames it takes for a user conditioning input (such as an arrow key press) to cause a change in a generated frame, but allows the model to use more denoising steps to create higher quality videos.
So cascading noise inference allows us to keep throughput high, while trading off latency and denoising steps. Naturally, this leads us to want to reduce the number of denoising steps to get latency down as much as possible! If we get to one-step denoising our cascading noise inference reduces to teacher forcing inference (Note even if the inference method is the same as teacher forcing here, our training method is different!)
It seems like we found a unifying representation to encompass many of the video generation training methods so far, but we still have some challenges:
- We still haven’t solved the root cause of exposure bias, leading to our generated videos still degrading in quality over time (although it seems to slow down the degradation)
- Our compute requirements grow as \(O(N^2)\) with the length of our video, making long video generation a challenge and often leading to videos not consistent over long time periods.
- We need to explore distillation for video generation so we can improve our latency (we want our world models to be as reactive as possible to our inputs)
The first exposure bias problem is tackled by a new training method called self forcing. The second distillation problem is tackled by causvid. The third long term consistency is problem is tackled by rolling forcing.
All of these have issues of their own and do not fully solve the problem they set out to address yet. I write about each below so feel free to skip around depending on which problem you are interested in.
What are some of the different losses used for video generators today (L2, GAN, DMD, SiD)?#
TL;DR: The loss function determines which direction of KL divergence you optimize:
- L2: Need corresponding ground truth data → Forward KL
- DMD: Need ground truth score (teacher model) → Reverse KL
- GAN: Need ground truth dataset → mix of both
- SiD: Under construction
▶ What is DMD loss?
DMD (Distribution Matching Distillation) loss is like the “reverse” version of L2 loss. While L2 works when you have ground truth to compare against, DMD works when you’re doing self rollout and generating videos from scratch - exactly the situation in self forcing.
The key idea is simple: train two diffusion models to estimate score functions:
- \(s_{real}\): a diffusion model trained on real videos from your dataset
- \(s_{fake}\): a diffusion model trained on fake videos generated by your model
Then use the difference between these scores as your learning signal:
$$ \nabla_\theta L_{DMD} \propto s_{fake}(x_t, t) - s_{real}(x_t, t) $$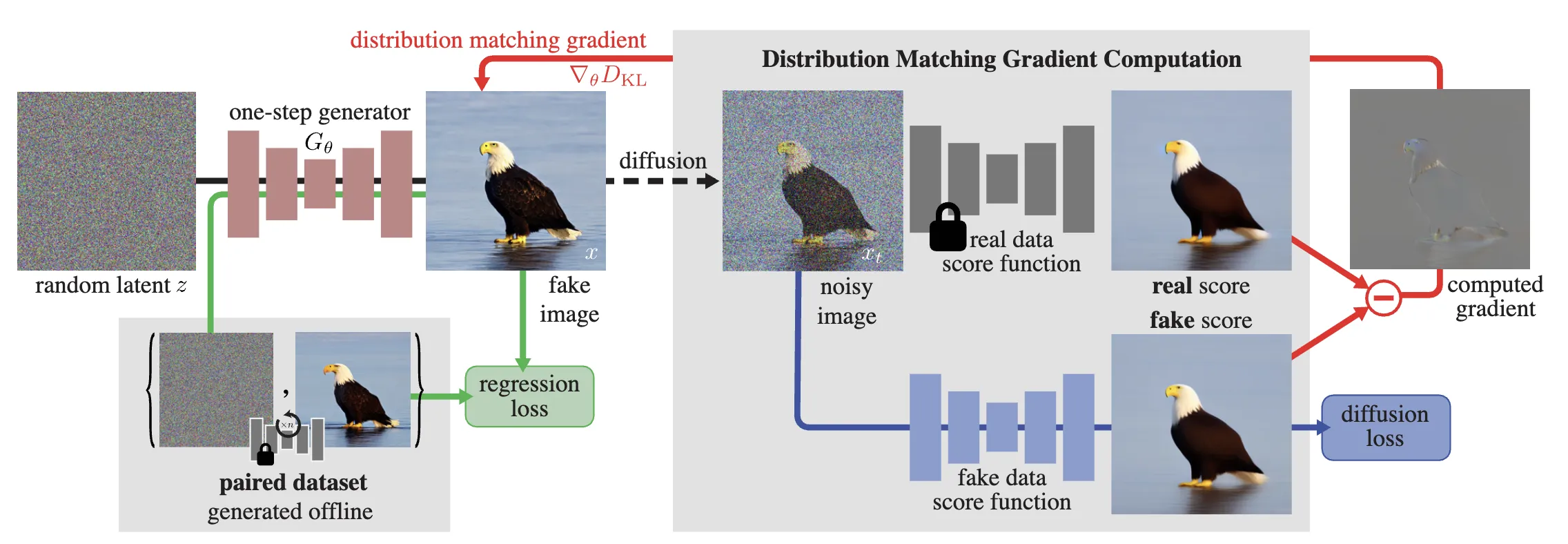
▶ Why does this work?
The DMD paper 3.2 shows this difference approximates the gradient of \( \mathrm{KL} (p_{fake} \parallel p_{real}) \) - the reverse KL divergence. Intuitively, \(s_{real}\) tells you “how to make this video more realistic” and \(s_{fake}\) tells you “how to make this video more fake”. The difference nudges your generator away from fake and toward real. If you train \(s_{fake}\) on your current generator outputs often, it will be a very good approximator of your generators scores. The reason why we cant just use the generators score directly is because our generator is a one (or few) step model so we cant query the score at an intermediate noise level.

Just like with GANs, we evaluate this at random noise levels across the denoising trajectory, giving us the expected reverse KL over noise levels:
$$ E_{backward} \Big[ \mathrm{KL}(p_{fake} \parallel p_{real}) \Big] $$The reason why we want to evaluate the loss at different noise levels is because for example if our generator is randomly initialized, our p_model will have very little overlap with p_data and so the scores are not well defined almost everywhere. (an intuitive example would be paintings by me vs by Van Gogh would look much more similar if we add a bunch of noise to them :) )
This makes DMD the natural pair for self forcing: SF handles the sampling (generating from scratch), while DMD handles the loss (learning without ground truth). Together they optimize reverse KL, which we show in detail below.
The explicit gradient formula for DMD (from DMD page 5) is:
$$ \nabla_\theta D_{KL} \simeq E_{z,t,x,x_t}\left[w_t \alpha_t \left(s_{\text{fake}}(x_t, t) - s_{\text{real}}(x_t, t)\right) \frac{dG}{d\theta}\right] $$where \(w_t\) and \(\alpha_t\) are weighting terms that depend on the noise schedule, and \(G\) is the generator network.
DF + L2 = minimize Forward KL#
TL;DR: DF trains on noisy ground truth frames. With L2 loss, this is equivalent to minimizing \(\mathrm{KL}(p_{data} \parallel p_{model})\) at each noise level (the same forward KL that DDPM optimizes for images).
DF + L2 is exactly what is implemented in the Diffusion Forcing paper. The algorithm is as follows:
- Sample a video \(x_0\) from your data distribution
- add independent noise per frame via the forward process
- Predict the L2 loss between the models prediction of the clean video and the actual clean video (note loss can be evaluated on the clean video or the noise added or the velocity. they are all equivalent up to a weighting of noise levels)
The paper goes into detail deriving showing that this algorithm is equivalent to minimizing Expected forward KL over noise levels assuming gaussian diffusion in appendix A.1. The paper justifies minimizing Expected forward KL over noise levels as a surrogate loss because it is an evidence lower bound for the expected log likelihood of the data under the forward process.
This is all well and good, but the ultimate result we care about is the expected log likelihood of the clean data. We don’t care about the log likelihood of the noisy latents.
If we start from trying to maximize the expected log likelihood of the clean data (don’t care about the noisy latents), we can derive a bit more general training process depending on the trajectories through noise that we care about.
Proof: DF + L2 and SF + DMD equivalence
TF + L2 = minimize Forward KL#
TF is a subset of DF so this should not be surprising. But instead of doing an expectation over the whole DF forward process our forward process allows a subset of the states of DF, so we only have a subset of the forward KL terms.
Since the only difference is the order in which frames are denoised this is still a forward KL loss.
BiD + L2 = minimize Forward KL#
Just like TF, BiD is a subset of DF. but it’s selecting the conceptual opposite of TF by denoising everything at the same time instead of denoising one at a time sequentially.
Since the only difference is the order in which frames are denoised this is still a forward KL loss.
SF + DMD = minimize Reverse KL#
TL;DR: SF trains on self-generated frames (no ground truth). DMD provides learning signals by comparing fake vs real score functions. Together they optimize reverse KL: \(\mathrm{KL}(p_{model} \parallel p_{data})\)—the opposite direction of L2 methods.
The proof is in Section 4 of the above proof for DF+L2
▶ a mistake in the self forcing paper algorithm
In the training algorithm presented in the Self Forcing paper, they sample a scalar timestep that is the same across frames, but in the actual code they sample independent timesteps per frame. This is an important distinction because if each frame didn’t have their own timestep like the concept in diffusion forcing, our autoregressive inference algorithm would always be out of distribution—the context frames would always be clean regardless of the denoising timestep for the very last frame we are denoising.

This notational inconsistency could be easily fixed by moving the timestep sampling inside the first for loop.
SF + GAN = JSD over noise#
TL;DR: SF generates fake videos. A discriminator learns to distinguish fake from real at random noise levels. This classic adversarial setup optimizes the expectation of Jensen-Shannon Divergence over noise levels.

Full proof: SF + GAN minimizes JSD over noise levels
The proof is heavily based on the original GAN paper and Diffusion-GAN paper.
The GAN loss for images is known to reduce to the JSD (feel free to see the proof in the original GAN paper )
So this result should be very intuitive as we are doing the straightforward way to train video generators with GANs with the small change of discriminating at random noise levels which results in an expectation of JSD over noise levels.
$$ E_{noise} \Big[ \operatorname{JSD}\big(p_{\text{data}}(x|t) \,\|\, p_{g}(x|t)\big) \Big] $$Causvid: Bridging DF and SF with DMD#
TL;DR: Causvid is a distillation method that pairs DF with DMD loss. Two versions exist:
- Approximated (DF+DMD): Uses ground truth frames as a computational shortcut. Creates a hybrid distribution that doesn’t fit cleanly into forward/reverse KL framework.
- Unapproximated (SF+DMD): Uses self-rollout, identical to SF+DMD → optimizes reverse KL.
SF + SiD = ?#
under construction.
Cited as:#
@article{ogata2025arvideo,
title = "The Autoregressive Video Generation Landscape (everything is min KL?)",
author = "Ogata, Mark",
journal = "markogata.com",
year = "2025",
month = "October",
url = "https://markogata.com/projects/2025/arvideolandscape/"
}
References#
Foundational Diffusion Papers:
[1] Ho, J., Jain, A., & Abbeel, P. (2020). Denoising Diffusion Probabilistic Models. NeurIPS 2020.
[2] Song, J., Meng, C., & Ermon, S. (2020). Denoising Diffusion Implicit Models. ICLR 2021.
[3] Song, Y., Sohl-Dickstein, J., Kingma, D. P., Kumar, A., Ermon, S., & Poole, B. (2021). Score-Based Generative Modeling through Stochastic Differential Equations. ICLR 2021.
[4] Karras, T., Aittala, M., Aila, T., & Laine, S. (2022). Elucidating the Design Space of Diffusion-Based Generative Models. NeurIPS 2022.
Video Generation Methods:
[5] Luo, G., Chen, T., Wei, S., Tang, W., Zhao, Y., Wang, X., Yang, L., & Liu, Z. (2024). Diffusion Forcing: Next-token Prediction Meets Full-Sequence Diffusion. arXiv preprint.
[6] Zheng, W., Wang, Y., Wang, K., Yang, Y., Li, W., & Liu, J. (2024). Self Forcing: Toward Unbiased and High-Quality Autoregressive Video Generation. arXiv preprint.
[7] Yin, T., Zhang, M., Luo, S., Luo, D., Schiff, Y., Yu, Y., Wang, Z., Gao, D., Ermon, S., & Zhang, Y. (2024). CausVid: Causal Video Generation. arXiv preprint.
[8] Jin, H., et al. (2025). Taming Teacher Forcing for Autoregressive Video Generation. arXiv preprint.
[9] Liu, B., et al. (2025). Wan: Open and Advanced Large-Scale Video Generative Models. arXiv preprint.
[10] Google DeepMind. (2024). Veo 3: Our Most Capable Image and Video Generation Models Yet. Technical Report.
Distillation Methods:
[11] Yin, T., Gharbi, M., Zhang, R., Shechtman, E., Durand, F., Freeman, W. T., & Park, T. (2023). One-step Diffusion with Distribution Matching Distillation. CVPR 2024.
[12] Yin, T., Gharbi, M., Shechtman, E., Durand, F., & Freeman, W. T. (2024). Improved Distribution Matching Distillation for Fast Image Synthesis. arXiv preprint.
[13] Kim, D., Shin, S., Song, J., Song, H., & Ermon, S. (2022). Diffusion-GAN: Training GANs with Diffusion. ICLR 2023.
Foundational GAN Paper:
[14] Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., & Bengio, Y. (2014). Generative Adversarial Networks. NeurIPS 2014.
Related Methods:
[15] Lamb, A. M., Goyal, A., Zhang, Y., Zhang, S., Courville, A. C., & Bengio, Y. (2016). Professor Forcing: A New Algorithm for Training Recurrent Networks. NeurIPS 2016.
Educational Resources:
[16] Weng, L. (2021). What are Diffusion Models? Lil’Log.
[17] Dieleman, S. (2024). Noise schedules considered harmful. sander.ai.
[18] Dieleman, S. (2024). Diffusion is spectral autoregression. sander.ai.
[19] Dieleman, S. (2024). The paradox of diffusion distillation. sander.ai.
[20] Liu, X., Gong, C., & Liu, Q. (2024). Rectified Flow: A New Paradigm for Generative Modeling. Project Page.
[21] Ruiqi Gao, Emiel Hoogeboom, Jonathan Heek, Valentin De Bortoli, Kevin P. Murphy, Tim Salimans (2024). Flow Matching: A Unifying View. Project Page.
Appendix#
This appendix contains detailed mathematical proofs for the claims in the main text. These derivations are optional—the main insights are captured above.
Proof 1: Unapproximated Causvid = Reverse KL#
Training Procedure#
The training procedure of unapproximated causvid involved the following:
- self-rollout, samples are generated by denoising pure noise using the generator.
- A guess of the clean image is sampled from the model at a random timestep during this generation.
- This prediction is noised using the forward process to a randomly picked noise level t: $$ x_t \sim F(G_\theta(z), t) $$ and DMD subtracts the score of the student \(s_{fake}\) and teacher \(s_{real}\) under this distribution, and sets this as the gradient for the generator.
This procedure is captured in the integral on the right hand side

from DMD2 eq (2)
- The expectation over t comes from picking a random noise level t to noise to
- z is a unit normal variable (pure noise image/video)
- \(G_\theta(z)\) is the clean image generated by our generators self rollout
- F is the forward process (just adding gaussian noise matching our noise level t)
- and \(s_{fake}\) \(s_{real}\) are the fake and real scores estimated by our generator network and teacher network respectively.
This is the gradient for the surrogate objective in DMD, which has an expectation over noise levels t in order to overlap the score distributions detailed in DMD section 3.2. Removing the gradient from both the left and middle of the above equation reveals the loss landscape \(L_{DMD}\) being optimized:
$$ E_{backward} \Big[ \mathrm{KL}(p_{fake} \parallel p_{\text{real}}) \Big] $$Hence, the unapproximated Causvid objective (SF + DMD) optimizes the expected reverse KL over all noise levels.
This makes sense as a surrogate to optimize, as removing the expectation over t would reduce the loss to minimizing the reverse KL (at the no noise level). i.e. minimizing the distance between the clean image/video distributions generated by the real world vs our model:

Conclusion#
$$ \text{Causvid unapproximated} = \text{SF+DMD} \quad\Rightarrow\quad \text{Reverse KL optimization} $$Proof 2: Approximated Causvid ≠ Linear Combination of Forward/Reverse KL#
Preliminaries#
Let
$$ x \sim p_{\text{data}}(x), \quad x_0 \sim p_{\text{model}}(x) $$$$ q(x_t \mid x_0), \quad p_\theta(x_{t-1} \mid x_t) $$with marginal noised states \(q_t(x_t)\).
We denote:
- DF (Diffusion Forcing): a diffusion-style method creating training samples from the data forward process.
- SF (Self Forcing): a method using self rollout to generate training samples from the model self-rollout process.
- DMD (Divergence Matching Distillation): a loss on score differences, marginalizing over the model distribution.
Forward + Reverse Hybrid under DF + DMD#
$$ x_t \sim q(x_t) = \int q(x_t \mid x_0) p_{\text{data}}(x_0) dx_0 $$and our model has a distribution over its outputs given a latent \(p_\theta(x_{0} \mid x_t)\).
so the resulting distribution of doing DF and then estimating \(\hat{x_0}\) using our model is:
$$ \hat{x_0} \sim r(\hat{x_0}) = \int p_\theta(\hat{x_0} \mid x_t) q(x_t \mid x_0) p_{\text{data}}(x_0) dx_0 $$Thus, the marginal distribution over training inputs is neither \(p_{\text{data}}\) nor \(p_\theta\), but a pushforward distribution. We write the DMD gradient update under this new distribution and compare it to the formulas for forward and reverse KL to see that our method can not be optimizing a loss landscape composed of a linear combination of forward/reverse KL divergences.
Proof: Approximated Causvid ≠ linear combination of forward/reverse KL
Conclusion#
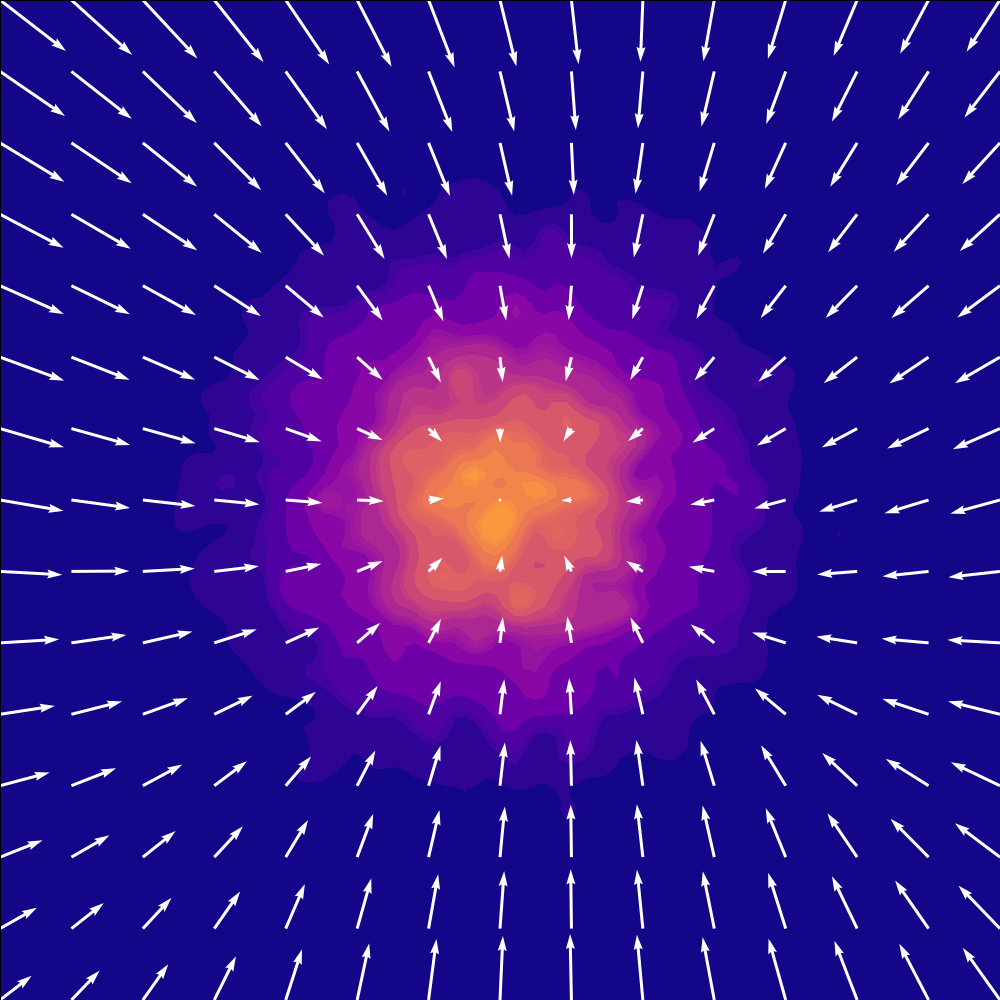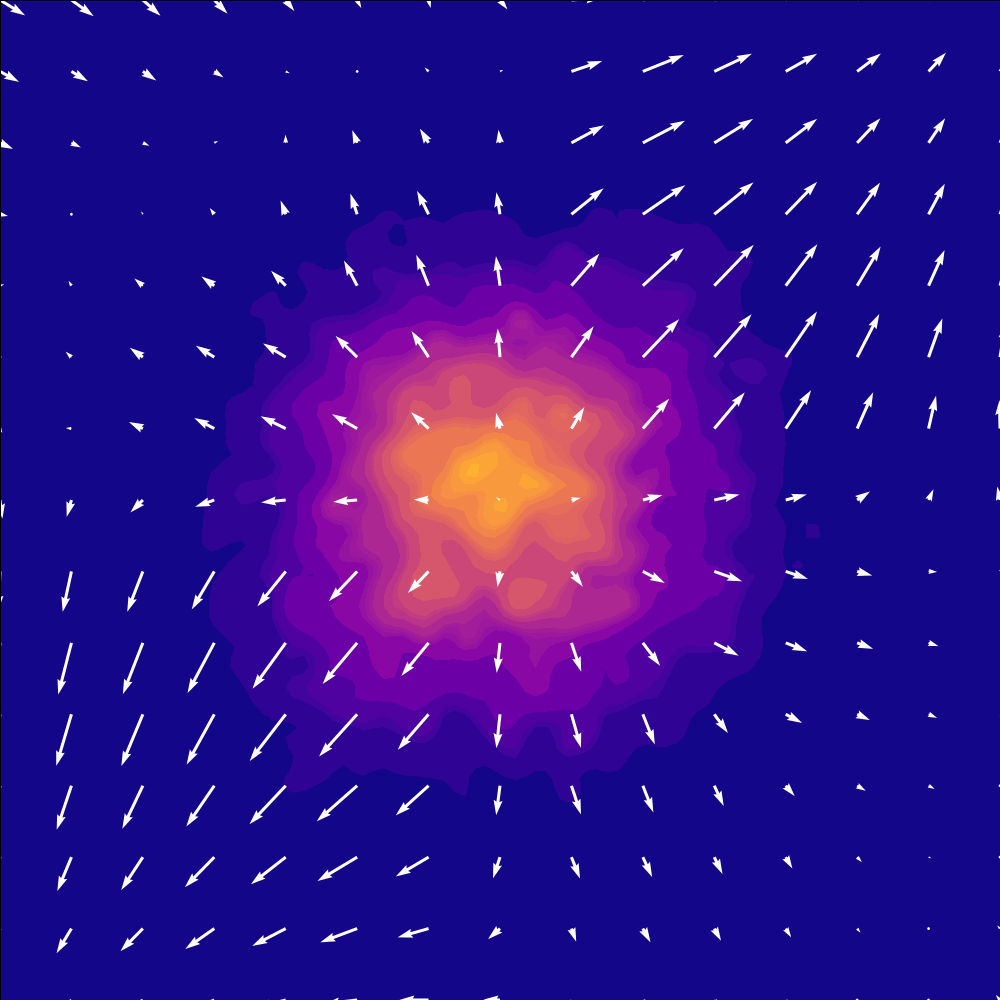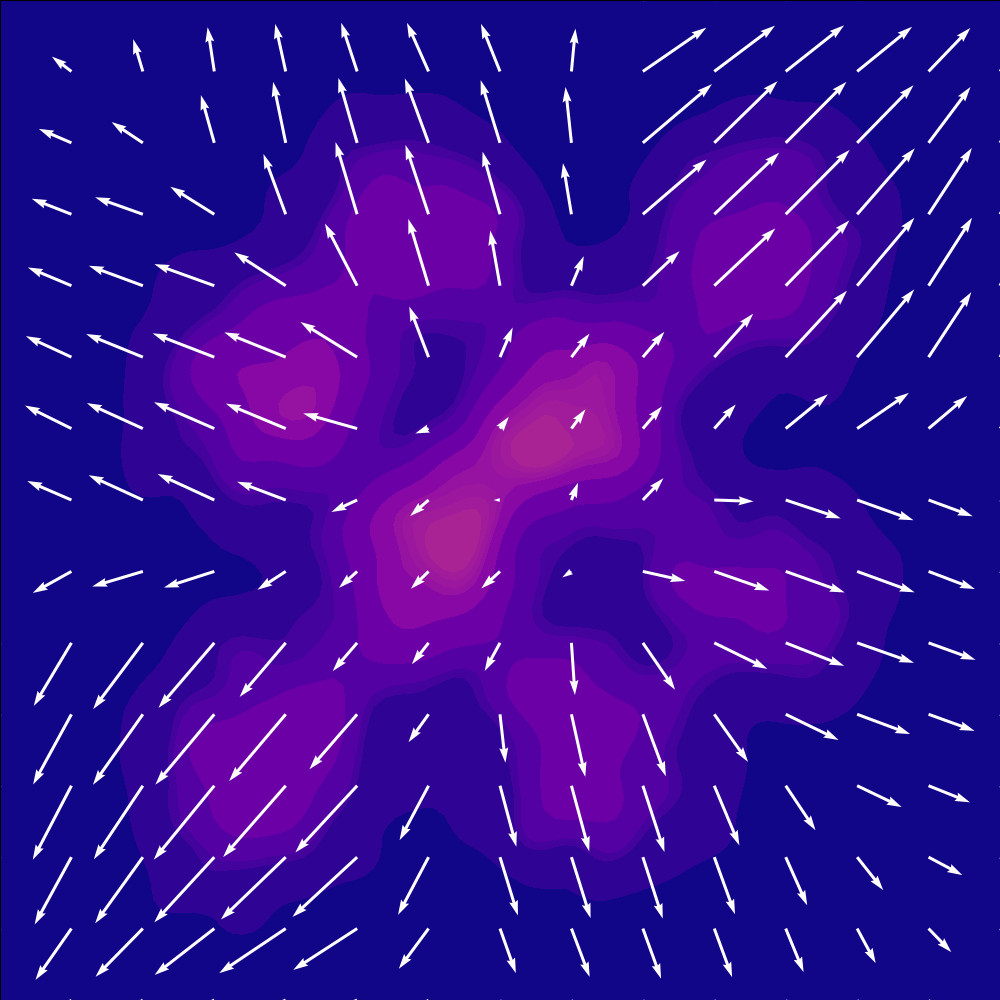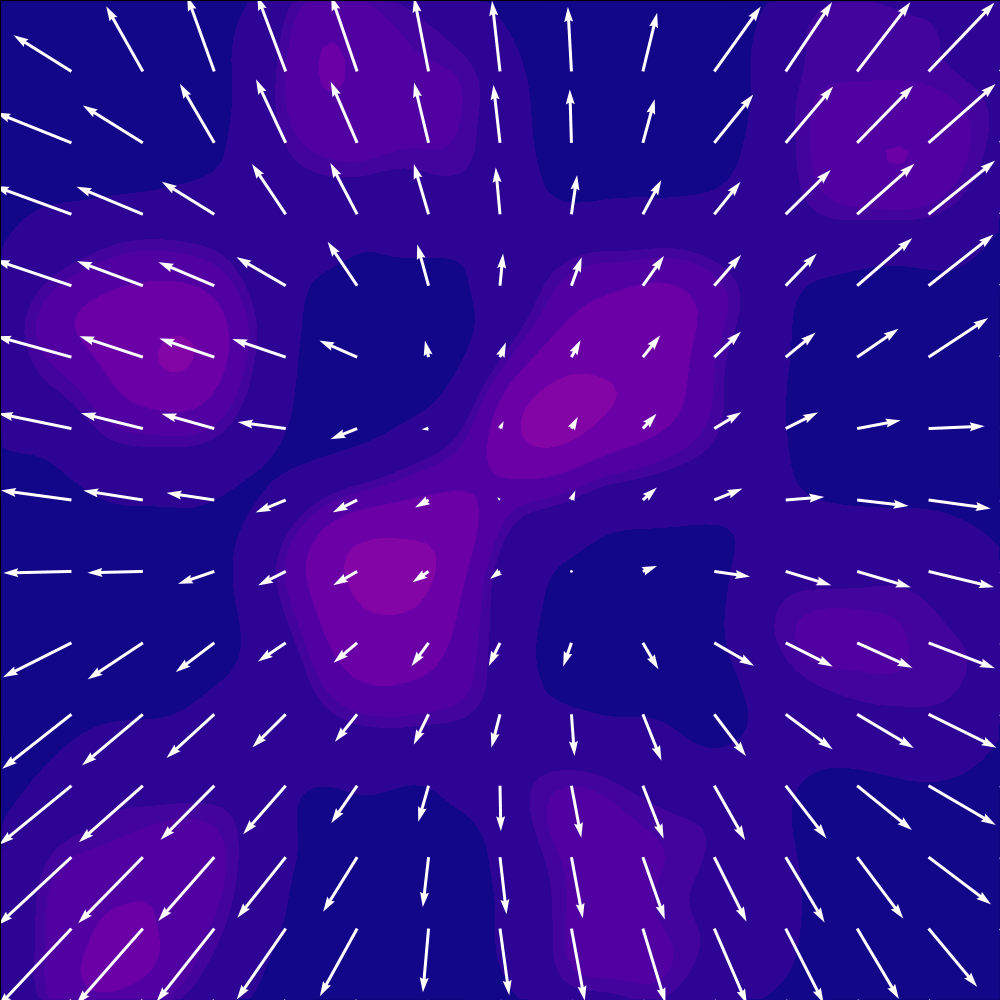
$$ \text{Causvid approximated} = \text{DF+DMD} \\ \quad\nRightarrow\quad \text{any convex combination of reverse and forward KL for non-trivial cases} $$cross entropy!#
here is a visualization of cross entropy for now