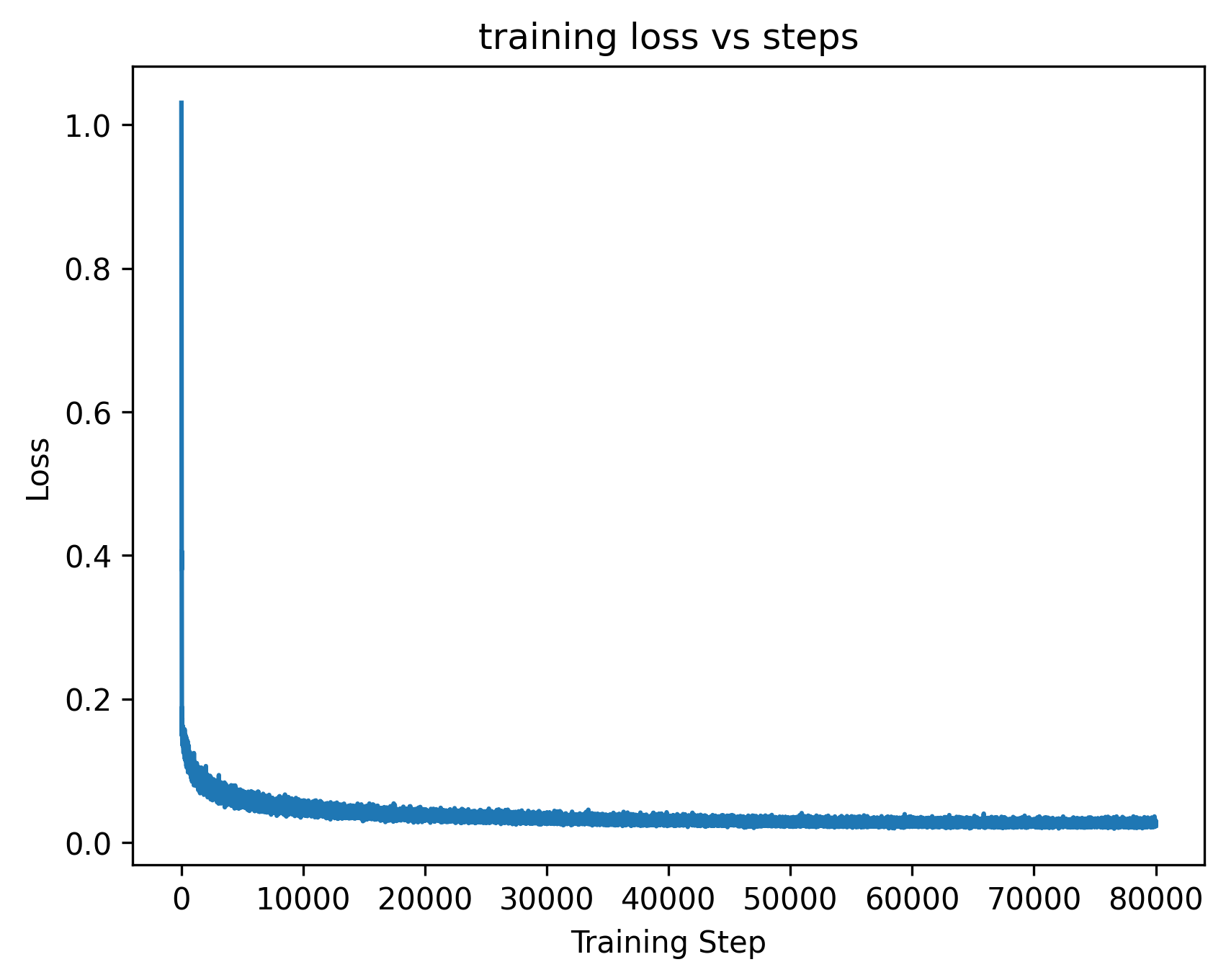
The Task: Push-T#
The goal of the Push-T environment is to push a T-shaped object into a target zone. The observation is 5D (positions of the T and the agent), and the action is a 2D vector for the agent’s next target position.
To make things efficient, we use Action Chunking: instead of predicting one action at a time, the policy predicts a “chunk” of \(K\) actions (here \(K = 8\)) to be executed open-loop.
1. MSE Policy (The Baseline)#
The simplest approach is to minimize the Mean Squared Error (MSE) between the predicted action chunk and the expert chunk. It works, but it struggles with the multi-modality of expert demonstrations.
MSE Rollouts (4 episodes)#
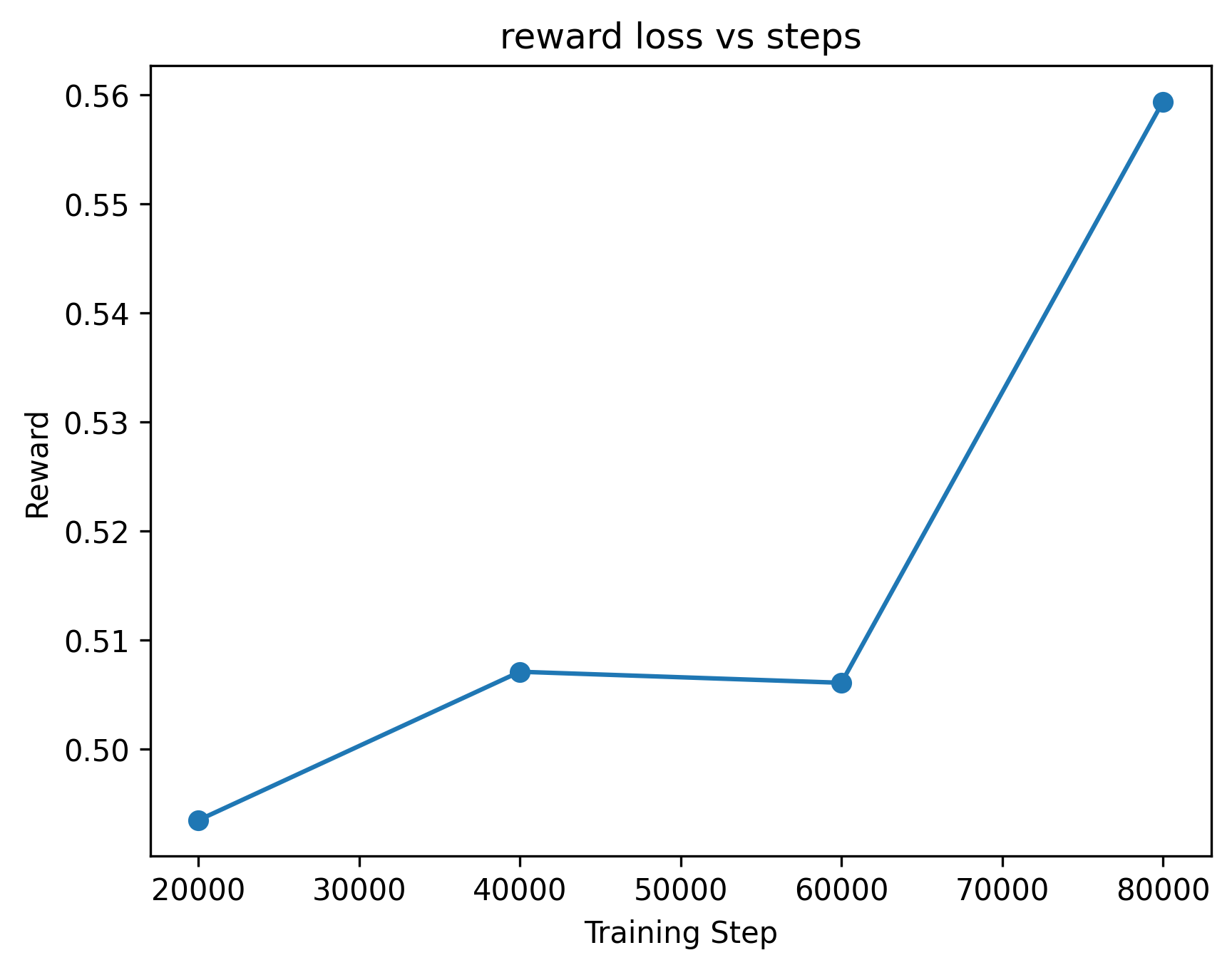
The MSE policy achieves a reward of around 0.56, which is decent but often fails to perfectly align the T.
2. Flow Matching Policy (The Upgrade)#
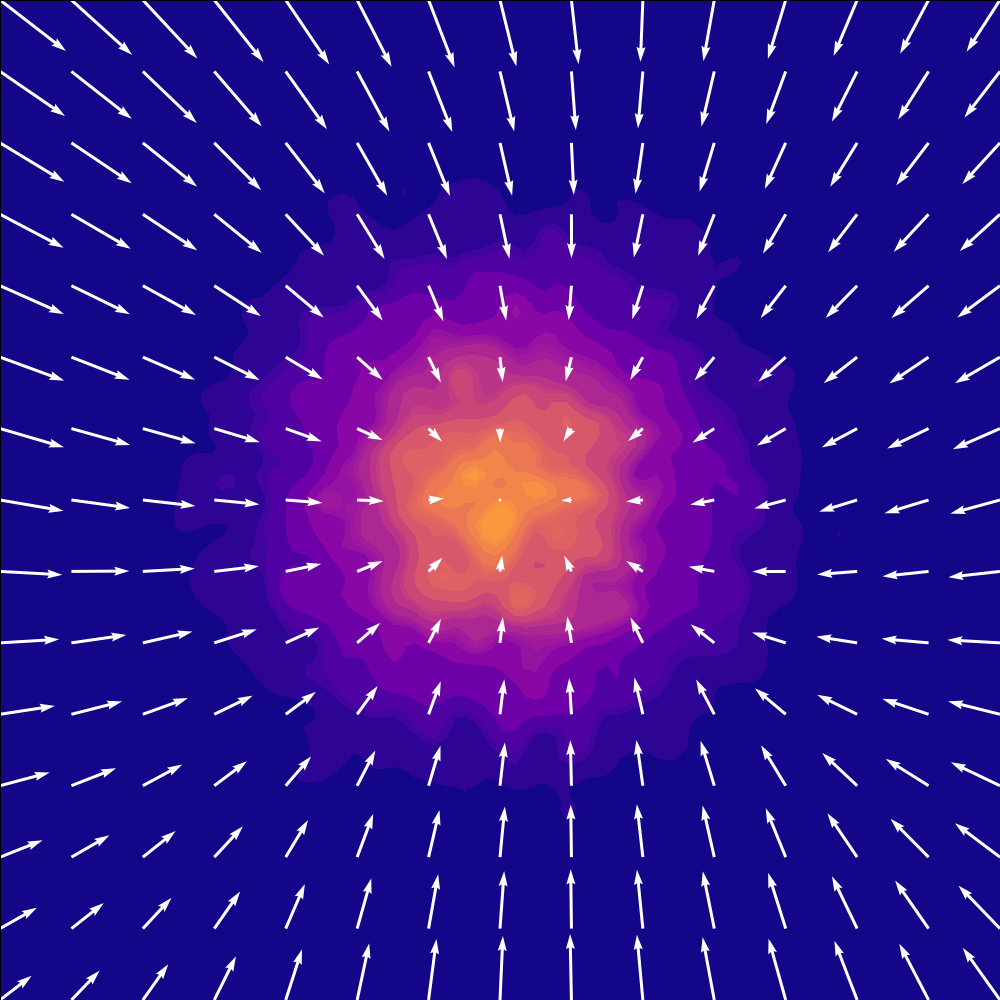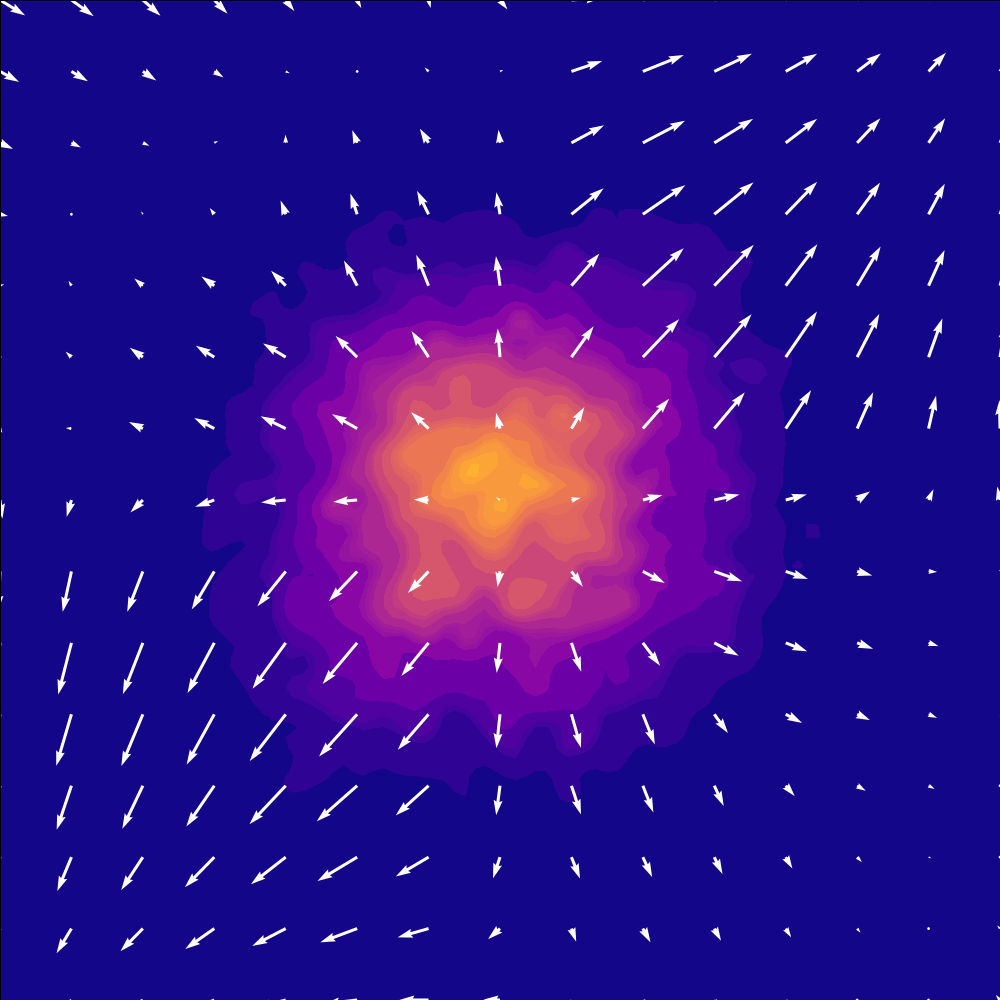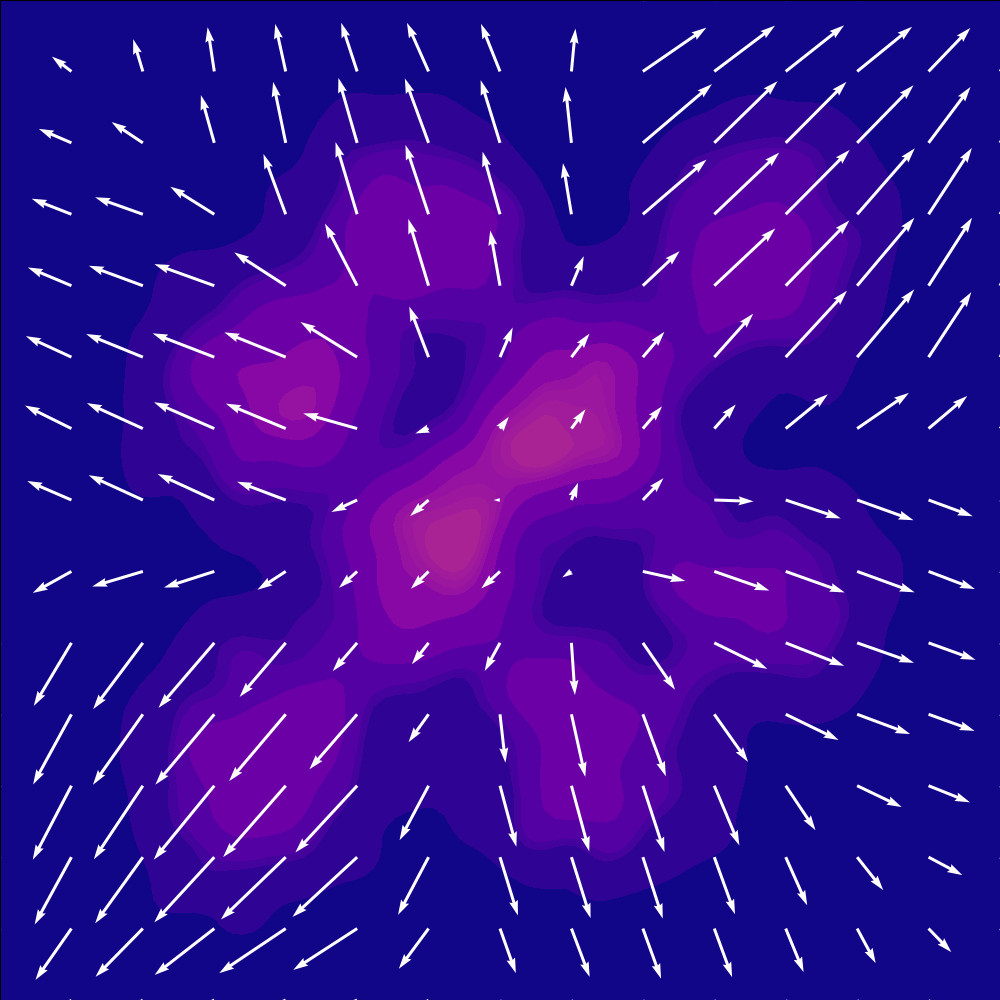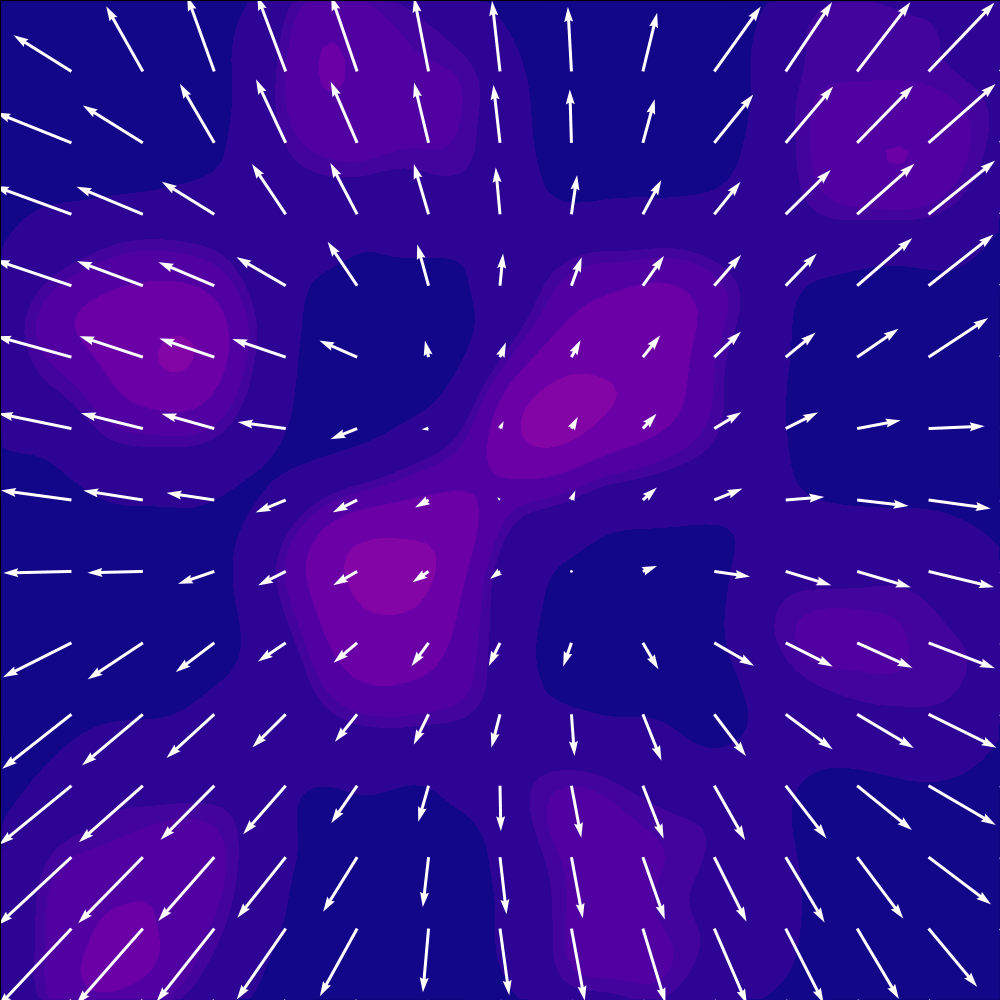
Flow matching addresses the limitations of MSE by learning a conditional vector field that transports noise into realistic action chunks. It’s similar to diffusion but often easier to train and faster to sample.
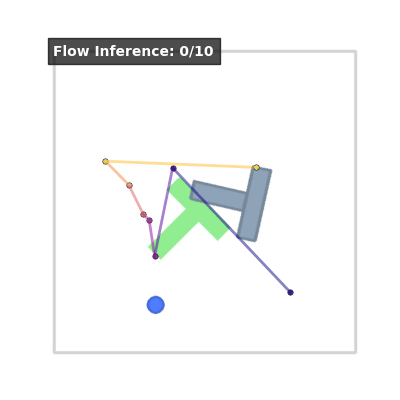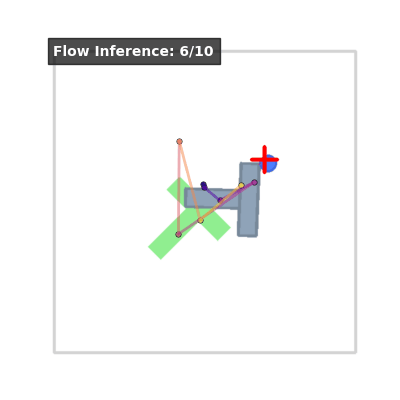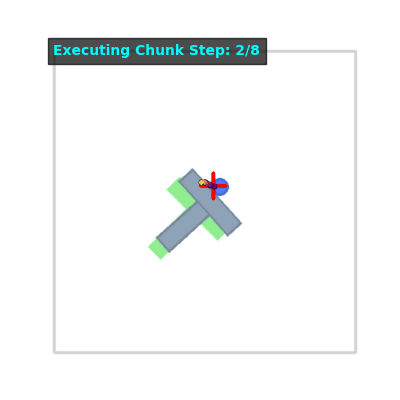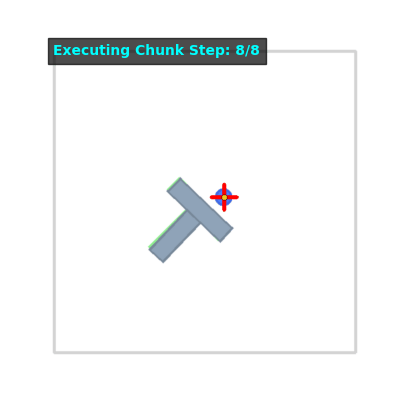
At inference time, we start with Gaussian noise and integrate the learned ODE to “flow” the noise into a precise action chunk. This is very similar to Diffusion Policy (Chi et al., 2025)
Inference Visualization#
Flow Matching Rollouts (4 episodes)#
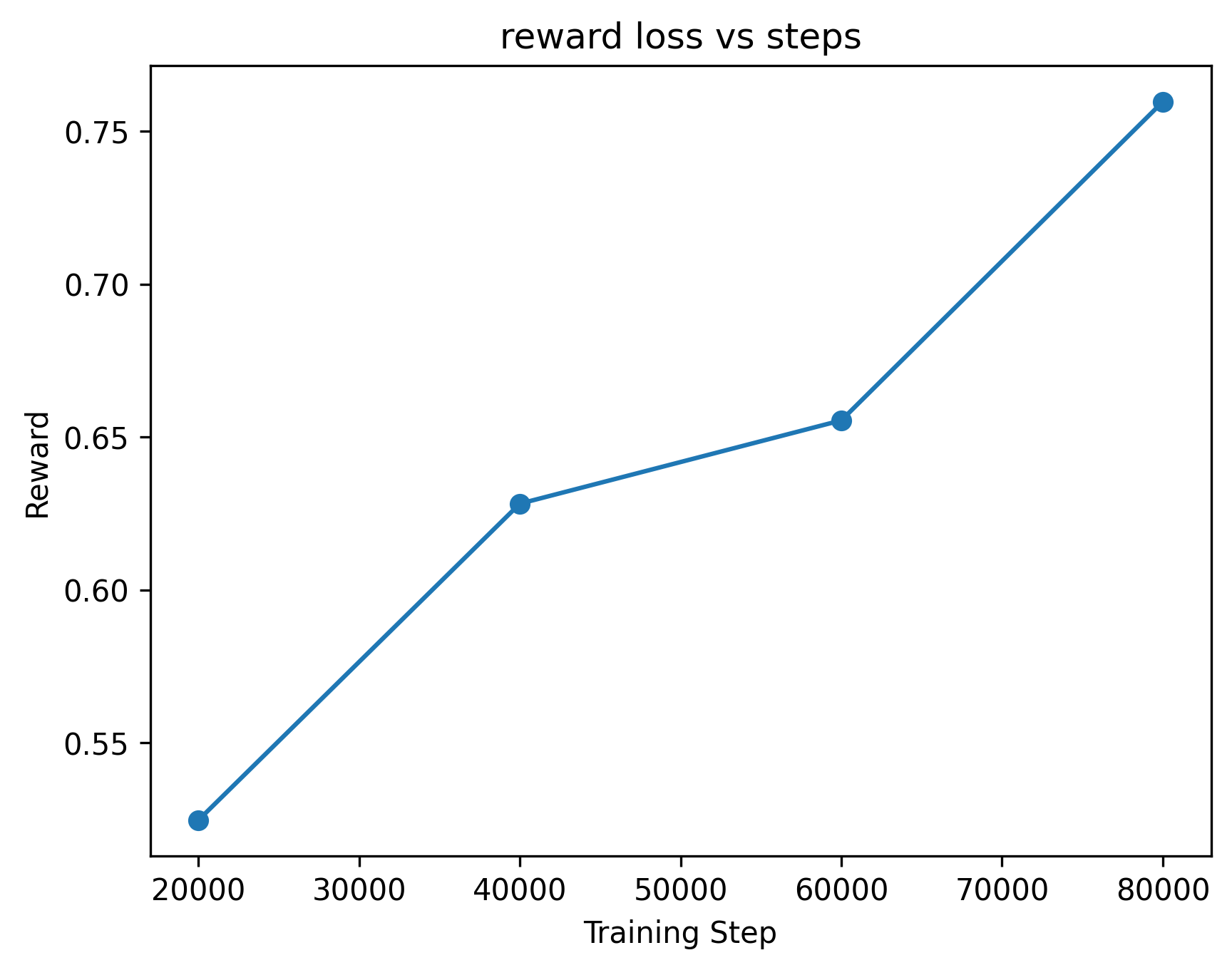
Flow Matching hits a reward of 0.75! It handles the complex trajectories much more gracefully than the MSE baseline.
3. Implementation Details#
The core of both policies is a Multilayer Perceptron (MLP) that processes the 5D environment observations.
- Architecture: 3 hidden layers.
- Hidden Size: 256 neurons per layer.
- Activation: ReLU functions after each hidden layer.
- Inputs: The network takes the 5D state (T-pos, agent-pos) as input. For the Flow Matching policy, it also takes the current timestep \(t\) and the noisy action chunk for a total input dimension size of state_dim + chunk_size * action_dim + 1.
- Output: The network predicts the velocity vector field (for Flow Matching) or the direct action chunk (for MSE). Both are the same dimension: chunk_size * aciton_dim
4. Qualitative Comparison#
- MSE Policy: Appears “hesitant” or “indecisive” in multi-modal situations. When the expert data shows multiple valid ways to push the T, the MSE objective forces the model to average these actions, often resulting in the agent moving towards a “mean” position that doesn’t actually help push the object. This leads to poor alignment.
- Flow Matching Policy: Much more “intentional” and “decisive.” It naturally follows a single high-probability trajectory from the expert distribution rather than averaging them. It handles the T-alignment with less hesitency, resulting in smoother, more human-like pushing motions. It also exhibits many rrepositioning or detour like motions to reposition itself compared to the mse policy.
Key Takeaways#
- Action Chunking is essential for high-frequency control tasks.
- MSE is a good “sanity check” but can be indecisive on multi-modal expert data.
- Flow Matching is a powerful alternative to learn mutlimodal action distributions in continuous spaces.