Background#
This assignment covers two families of off-policy Q-learning algorithms:
DQN learns a Q-function \(Q_\phi(s, a)\) over discrete actions and derives a policy by acting greedily: \(\pi(s) = \arg\max_a Q_\phi(s, a)\). The Q-function is trained via the Bellman backup:
$$Q_\phi(s, a) \leftarrow r + \gamma \max_{a'} Q_{\phi'}(s', a')$$where \(\phi’\) are target network parameters. Double-Q learning addresses overestimation by decoupling action selection from evaluation: the online network picks the action, but the target network evaluates it.
SAC extends Q-learning to continuous actions with an entropy-regularized objective. We learn a policy that predicts the max reward action because taking a max over continuous action space is intractable:
$$J(\pi) = \sum_t \mathbb{E}\left[r(s_t, a_t) + \alpha \mathcal{H}(\pi(\cdot|s_t))\right]$$where \(\alpha\) is a temperature parameter controlling the exploration-exploitation tradeoff. Actions are sampled via the reparameterization trick, and clipped double-Q critics take the minimum of two Q-networks to reduce overestimation.
Part 1: DQN#
2.4 Basic DQN on CartPole#
A vanilla DQN agent on CartPole-v1. The agent briefly reaches the maximum return of 500 around 25–35K steps, but then collapses to ~100 and never recovers.


To test whether Q-value overestimation is the cause, I ran the same setup with double-Q learning enabled.
Double-Q also dips mid-training and recovers, albiet sporadically, to 500 reward while vanilla DQN stays stuck at ~100. This shows overestimation bias is contributing to the collapse but isnt the whole story, and fixing it doesnt solve instability completely.

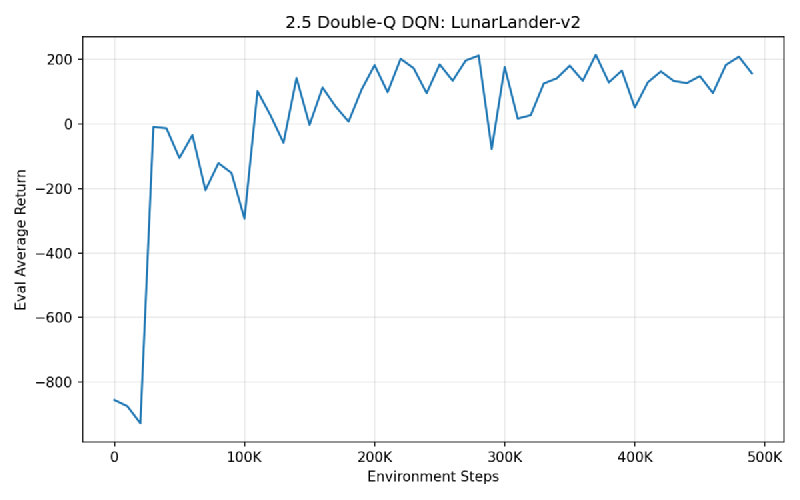
2.5 Double-Q DQN on LunarLander#
Adding double-Q learning to reduce overestimation bias. The agent learns to land successfully, climbing from -900 to ~200 average return over 500K steps.

2.5 DQN on MsPacman (Atari)#
Scaling DQN to pixel observations with a convolutional encoder. Train episode returns (light blue) show high variance due to epsilon-greedy exploration, and eval returns (orange) climb to ~2000 over 1M steps.
Early eval returns underperform train returns because at the start, the training policy is completely random (epsilon = 1) while the eval policy is greedy (epsilon = 0). A bad deterministic policy gets worse returns than a completely random policy in pacman because a completely random policy will encounter pellets just by moving around randomely, but a bad deterministic one (like one that keeps going left into a wall, effectively not moving) is less likely to get rewards on accident while the odds of dying to a ghost is similar in both cases. This phenomina gets fixed when the policy improves.

Greedy Policy Rollout#
2.6 Hyperparameter Study: Network Depth#
Comparing 1, 2, and 4-layer Q-networks on LunarLander. I was curious wether the representative capacity makes the return platou or converge faster. All depths trained very similary suggesting that Q=learning is not that snesitive to representative capacity/complexity.




All three depths learn successful landing policies, consistent with the training curves converging to similar performance.
Part 2: Soft Actor-Critic#
3.4 SAC on HalfCheetah#
A full SAC agent with entropy bonus, reparameterized policy gradients, and Polyak-averaged target critics. The agent steadily improves to ~7500 return over 500K steps, with a notable dip around 200K that it recovers from.

Fixed Temperature Rollout (α=0.1)#

3.5 Automatic Temperature Tuning#
Instead of fixing \(\alpha\), we can learn it via dual gradient descent to maintain a target entropy \(\bar{\mathcal{H}} = -\dim(\mathcal{A})\):
$$\alpha^* = \arg\min_\alpha \; \mathbb{E}_{a \sim \pi}\left[-\alpha \left(\log \pi(a|s) + \bar{\mathcal{H}}\right)\right]$$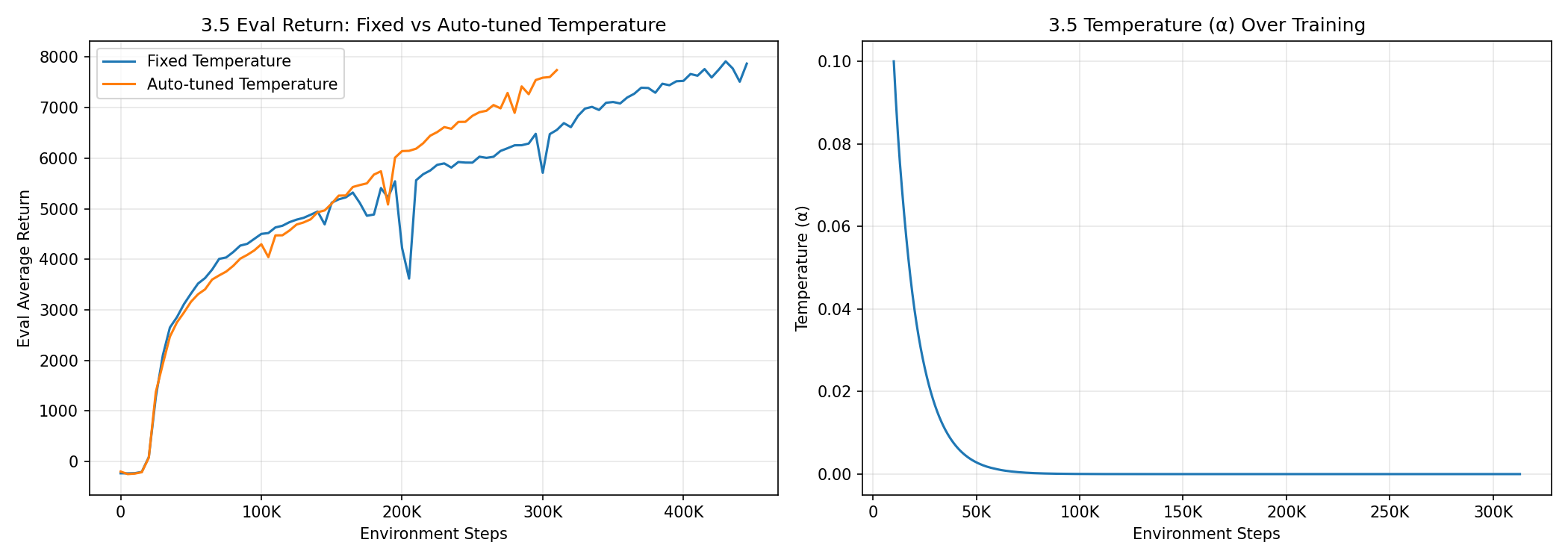
Does auto-tuning help? Yes — it achieves slightly superior performance and learns more smoothly without the mid-training dip seen in the fixed-temperature run.
How does temperature evolve? It decreases rapidly from 0.1 to near zero within the first 50K steps, then stabilizes. This makes sense: HalfCheetah’s optimal policy is fairly deterministic, so the agent quickly learns that it doesn’t need much exploration entropy and the soft constraint on minimum entropy becomes easy to satisfy at low \(\alpha\).
Auto-tuned Rollout#

3.6 Clipped Double-Q vs Single-Q on Hopper#
Comparing single-Q (mean of critics) vs clipped double-Q (min of critics) on Hopper-v4.
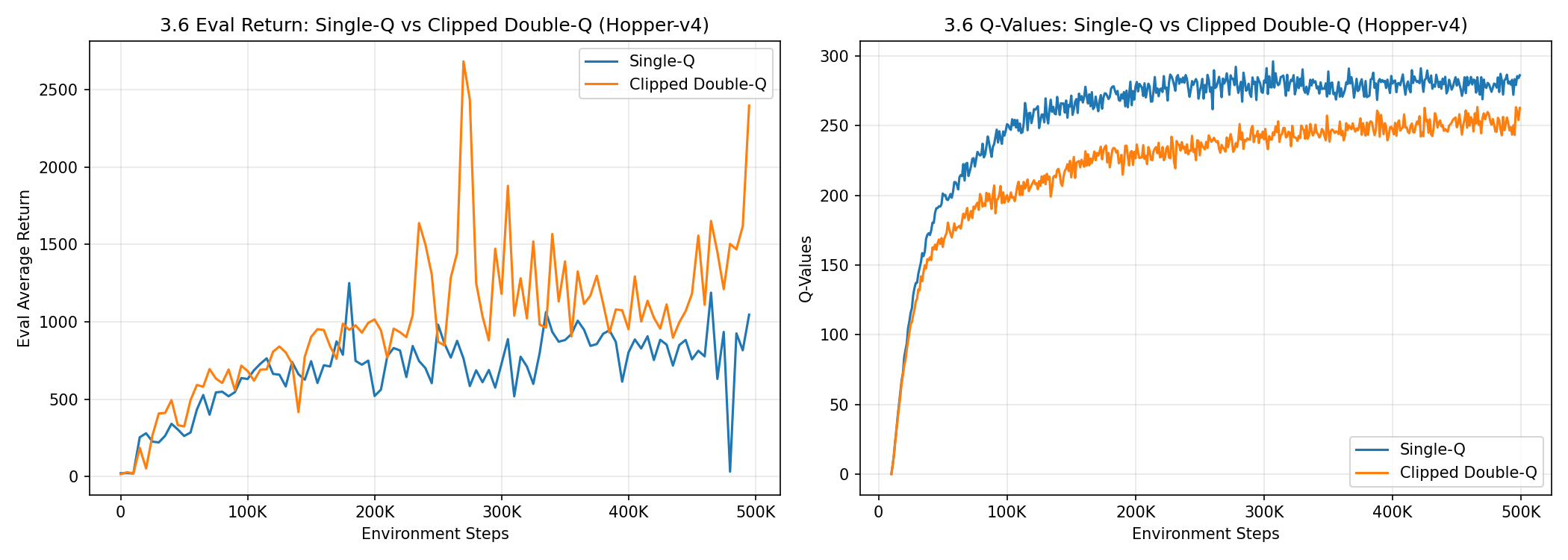
The clipped double-Q agent achieves significantly higher returns, reaching ~2800 vs the single-Q agent’s ~1500. The Q-value plot tells the story: the single-Q critic’s estimates are consistently higher than the clipped variant, indicating overestimation. The clipped Q-values grow steadily without plateauing, mirroring the continued improvement in eval returns. Meanwhile, the single-Q values plateau early — the inflated value estimates provide a misleading gradient signal that causes the policy to stagnate.
This is a textbook demonstration of overestimation bias: by taking the minimum of two critics, clipped double-Q provides more conservative (and accurate) value targets, which translate to better policy updates.


SAC vs Policy Gradients on HalfCheetah#
How does SAC compare to the policy gradient agent from HW2? Here’s a side-by-side of the learned policies:


The difference is stark. The policy gradient agent manages an awkward shuffle, while SAC produces a smooth, fast running gait with ~7800 return. Off-policy learning with a replay buffer is far more sample-efficient: SAC reuses every transition many times, while policy gradients discard data after each update.
Key Takeaways#
- Double-Q learning is a simple but effective fix for Q-value overestimation in both DQN and SAC.
- Entropy regularization in SAC provides principled exploration without \(\epsilon\)-greedy heuristics.
- Automatic temperature tuning removes a sensitive hyperparameter and can match or beat hand-tuned values.
- Clipped double-Q critics are essential for stable SAC training — overestimated Q-values lead to stagnant policies.
- Network depth matters less than expected for simple environments, but deeper networks can accelerate early learning.
Training with Modal#
I used modal AI for the first time to train the cheetah runs.
I went from debugging the trianing loop on my macbook to sending my run to a gpu in the cloud for my “serious training run” while I got lunch very easily!