I watched Andrej Karpathy’s video on tokenization and decided to build a tokenizer based on a rapper I enjoy: Logic.
The tokenizer is hosted on hugging face so please have a try!
I manually copy-pasted the lyrics of the top 10 songs from logic into a text file, and then ran the BPE algorithm to find a tokenization. I set the vocab size to 1024 with the original being 256 (utf-8).
One funny thing I noticed was usually the compression ratio is below 2, but if you input a rap sounding line (maybe with some profanity), the compression ratio goes to around 3.
Thats expected because the training set has lots of that kind of data, but still pretty funny.
I tested out how the vocab size effects the compression ratio when the entire training set is passed in and got a nice curve.
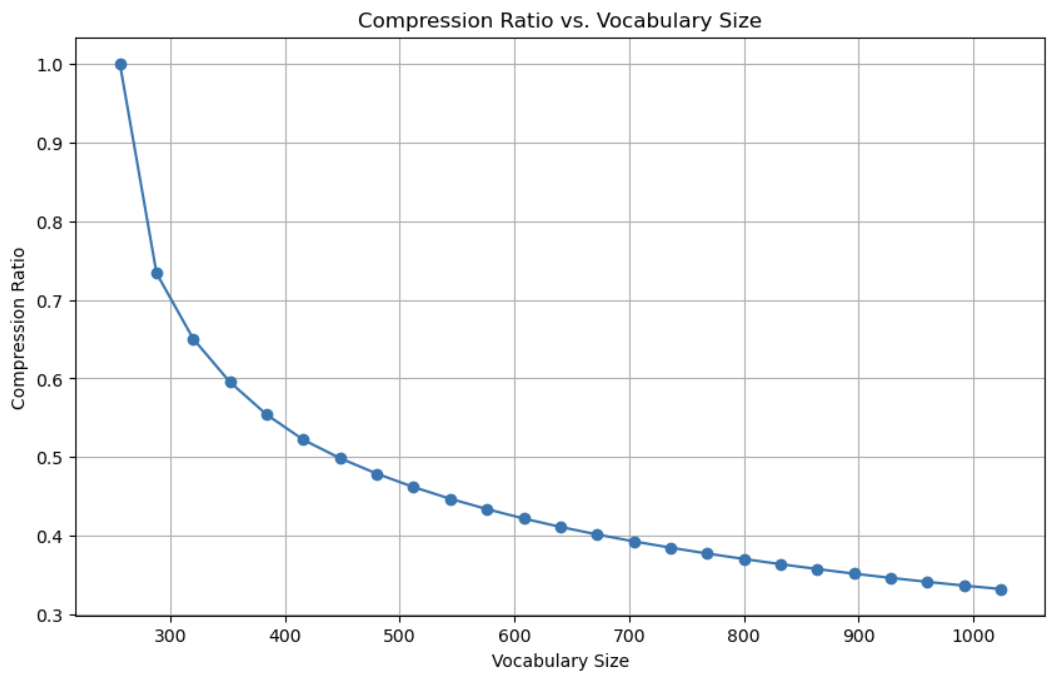
A vocab size of 1024 which is quadruple the original utf-8 encoding vocabulary results in around 3x compression.
If you try out regular english sentences, the compression ratio sits at around 2 (try it on huggingface with above link).
So vocab size of 1024 is probably overfitting.